As part of this project we bulk imported around 7000 videos to our PeerTube instance. We succesfully achieved this by using a Python script that uses the PeerTube API. Before we get into the technical details of this script, we will share some general conclusions and recommendations first.
Check existing tools
Before thinking about creating your own tool to do things like bulk importing videos, it’s wise to check the existing official CLI tools that are part of PeerTube. These tools are tried and tested and are supported by the PeerTube community.
One of these tools is peertube-import-videos.js, which comes close to what we wanted, but we imported videos from a platform which is not supported by this tool.
You can use this script to import videos from all supported sites of youtube-dl into PeerTube.
Setup your default configuration
As an admin of your instance you have to setup your preferred configuration for video uploads. After logging in as an admin you can navigate to Administration > Configuration > Basic > Videos and set ‘Allow import with HTTP URL (e.g. YouTube)’ if you are importing this way. More importantly you have to decide how you want your videos transcoded for playback through Administration > Configuration > VOD Transcoding as this has quite an impact on your available storage.
We decided on the following configuration after careful consideration.
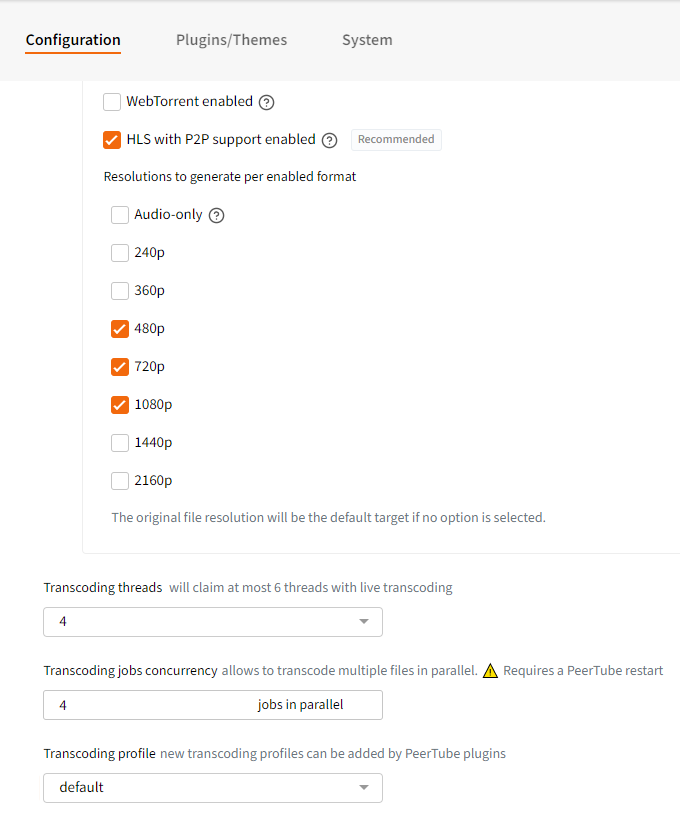
We chose the recommended ‘HLS with P2P support enabled’ instead of the default ‘Webtorrent enabled’ for reasons that are stated in the help text (behind the question mark icon):
Requires ffmpeg >= 4.1 Generate HLS playlists and fragmented MP4 files resulting in a better playback than with plain WebTorrent:
Resolution change is smoother Faster playback especially with long videos More stable playback (less bugs/infinite loading) If you also enabled WebTorrent support, it will multiply videos storage by 2
Using the PeerTube API
When using the PeerTube API there is a couple of things you need to be aware of:
- The API documentation is not always complete and accurate
- PeerTube and it’s API are still under development
- All API calls are throttled
When testing our scripts/tools that utilise the PeerTube API, we noticed some inconsistencies, omissions and even discovered some small bugs. A lot of our findings found it’s way back into fixes in the documentation and source code, by submitting pull requests upstream.
As PeerTube is still in development towards v4 and new features are being added, the API and it’s documentation is still a moving object. When you upgrade your PeerTube instance, always re-test your script/tool and adapt accordingly.
Since v2 of PeerTube, API throttling was introduced to prevent user-agents (like bots) to “hammer your API” and have a negative impact on the performance of your instance. In your main production configuration file, this shows the rates limits:
rates_limit:
api:
# 50 attempts in 10 seconds
window: 10 seconds
max: 50
login:
# 15 attempts in 5 min
window: 5 minutes
max: 15
signup:
# 2 attempts in 5 min (only succeeded attempts are taken into account)
window: 5 minutes
max: 2
ask_send_email:
# 3 attempts in 5 min
window: 5 minutes
max: 3
When bulk importing videos we needed to take this into account as each video import needs a separate API call. We implemented a 1 second pause between each API call in our script to be on the safe side.
Failed imports
Of all the 7000 videos we imported only a dozen or so failed. All of those failed, not because of PeerTube or our script, but because of problems with the data source.
As data source we used a CSV file that was generated by exporting data (harvesting of OAI-PMH) from the openbeelden.nl platform. In this dataset of 7000 videos there were some odd and unexpected data inconsistencies and even a couple of missing video files that have been unnoticed for years.
Our videos had a lot of tags added to them and we already knew we could only use a maximum of 5 tags for a video in PeerTube, so we scripted it to reduce it to use the first 5 tags. What we missed was that these 5 tags also have to be unique, which we assumed they were, but apparently not in our data.
The error reporting of the PeerTube API is pretty good, so you can see why the import failed. For every failed import we appended the source data to a seperate CSV file in our script, so we could fix the data and import it again.